Dieser Artikel untersucht die Leistung großer Sprachmodelle (LLMs) wie ChatGPT4-Turbo und ChatGPT4-Omni bei Aufgaben zur Informationsextraktion und vergleicht sie mit dem spezialisierten E-MailParser von LangTec. Unsere Analyse zeigt, dass ein speziell entwickeltes System zum Dokumentverstehen die führenden LLMs in dieser wichtigen Business-Aufgabe um Längen schlägt.
Benchmarking der Genauigkeit
Um die Genauigkeit von ChatGPT4-Turbo, ChatGPT4-Omni und LangTecs E-MailParser zu bewerten, wurde eine umfassende Bewertung mit 20 Dokumenten über vier Extraktionsaufgaben hinweg durchgeführt:
- Q88: Überprüfungsfragebögen für Tankerinformationen
- Timesheet: Lade-/Entladeberichte von Tankern
- Ship: Anfragen für kommerzielle Frachttransporte
- Cargo: Positionierungslisten kommerzieller Frachtschiffe
Aus jedem dieser Dokumente extrahierten wir etwa 20 Ziel-Datenpunkte. Für die Bewertung hatten diese Dokumente vordefinierte Ground-Truth-Labels, die die erwarteten Zielwerte für jedes Feld angaben. Durch den Vergleich der extrahierten Werte mit diesen Ground-Truth-Labels konnten wir die Genauigkeit für jedes Modell berechnen.
Benchmark-Ergebnisse: LLMs vs. LangTecs E-MailParser
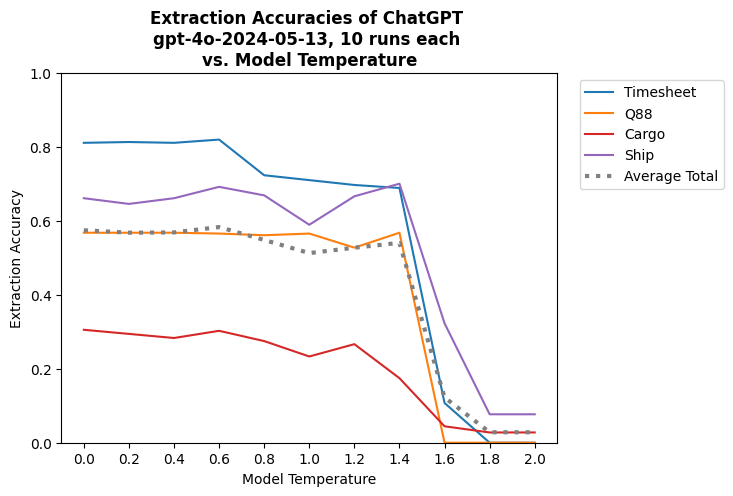
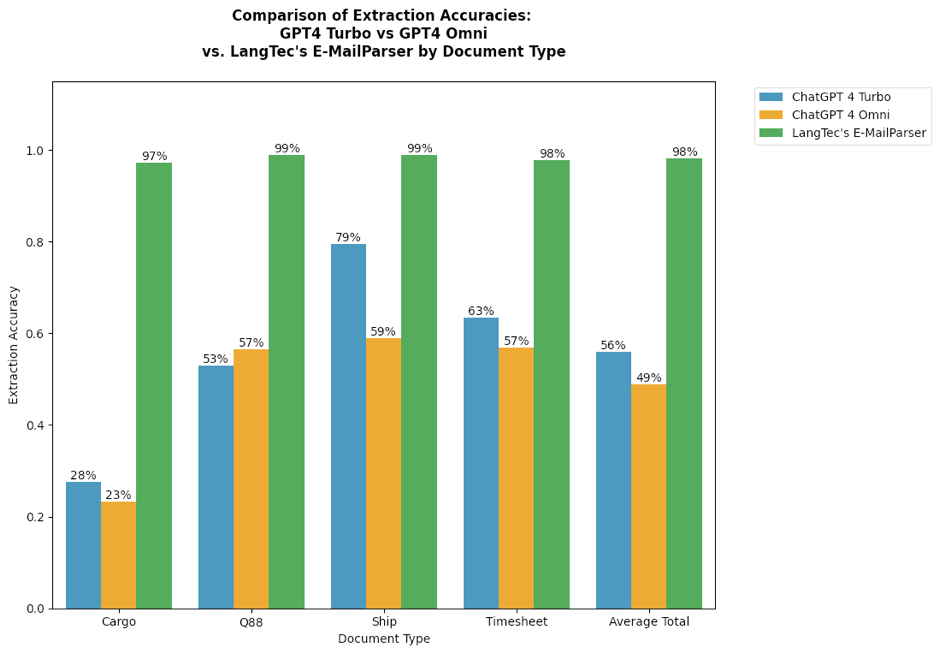
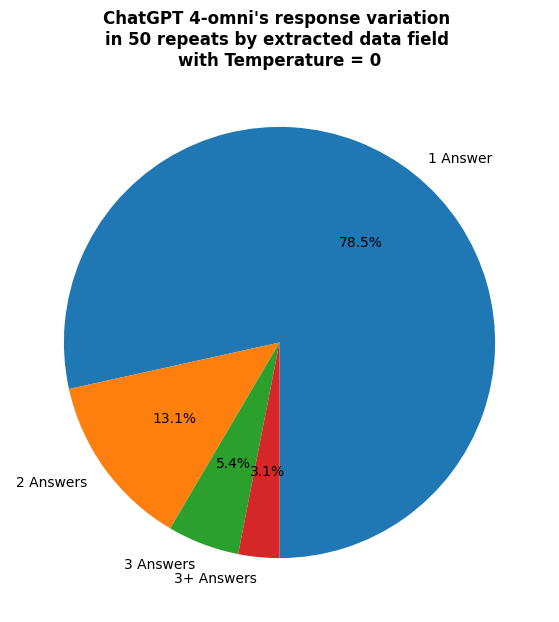
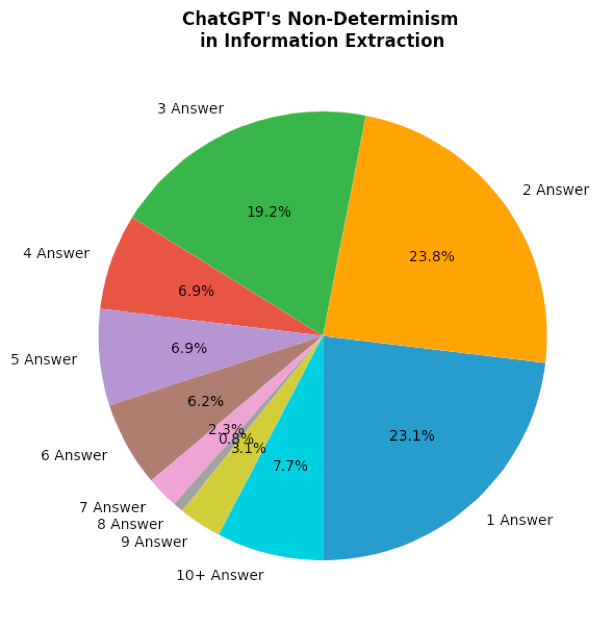
Sowohl ChatGPT4-Turbo als auch ChatGPT4-Omni zeigen ein gewisses Maß an Genauigkeit bei Aufgaben zur Informationsextraktion und erreichen Gesamtwerte von 56 % bzw. 49 %. Bemerkenswert ist, dass das neuere Modell ChatGPT4-Omni bei dieser Aufgabe für die meisten Dokumententypen schlechter abschneidet als sein Vorgänger ChatGPT4-Turbo. Eine weitere wichtige Beobachtung war, dass die Leistung der Modelle durch Inkonsistenz beeinträchtigt wird. Für denselben Eingabetext und dieselbe Extraktionsaufgabe liefern diese Modelle jedes Mal unterschiedliche Antworten, selbst wenn dieselbe Frage gestellt wird. Dieses nicht-deterministische Verhalten macht sie unzuverlässig für Szenarien, in denen konsistente und genaue Informationsbeschaffung entscheidend ist.
Im Gegensatz dazu zeigen spezialisierte Parser wie LangTecs E-MailParser eine deutlich höhere Genauigkeit, sind in ihrem Verhalten vollständig deterministisch und erreichen konstant 98 % Extraktionsgenauigkeit über verschiedene Dokumentenformate hinweg. Diese Zuverlässigkeit macht eine deterministische Lösung zur Dokumentenverständnis wie E-MailParser zu einer verlässlicheren Lösung für Aufgaben zur Informationsextraktion, insbesondere bei der Verarbeitung vielfältiger E-Mail-Inhalte in geschäftskritischen Anwendungen.
Abschluss
Während LLMs wie ChatGPT hervorragend zum Generieren von Inhalten geeignet sind, weisen sie erhebliche Einschränkungen auf, insbesondere in Szenarien, die deterministische Ausgaben erfordern, wie z. B. Aufgaben zur Informationsextraktion. Für solche Anwendungen bieten Dokumentenverständnis-Lösungen wie LangTecs E-MailParser eine zuverlässigere und genauere Lösung.