This article examines the performance of large language models (LLMs) like ChatGPT4-Turbo and ChatGPT4-Omni for information extraction tasks, comparing them with LangTec’s specialized E-MailParser. Our analysis reveals significant limitations of LLMs in this domain.
Benchmarking Accuracy Scores
To benchmark the accuracy of ChatGPT4-Turbo, ChatGPT4-Omni, and LangTec’s E-MailParser, we conducted a comprehensive evaluation using 20 documents across four extraction tasks:
- Q88: Vetting Questionnaires for Tanker Information
- Timesheet: Tanker Loading/Unloading Statements of Fact
- Ship: Requests for Commercial Cargo Shipping
- Cargo: Commercial Cargo Vessel Position Lists
From each of these documents we extracted about 20 target data points. For the evaluation,These documents had predefined ground truth labels, indicating the expected target values for each field. By comparing the extracted values to these ground truth labels, we were able to calculate accuracy scores for each model.
Benchmark Results: LLMs vs. LangTec’s E-MailParser
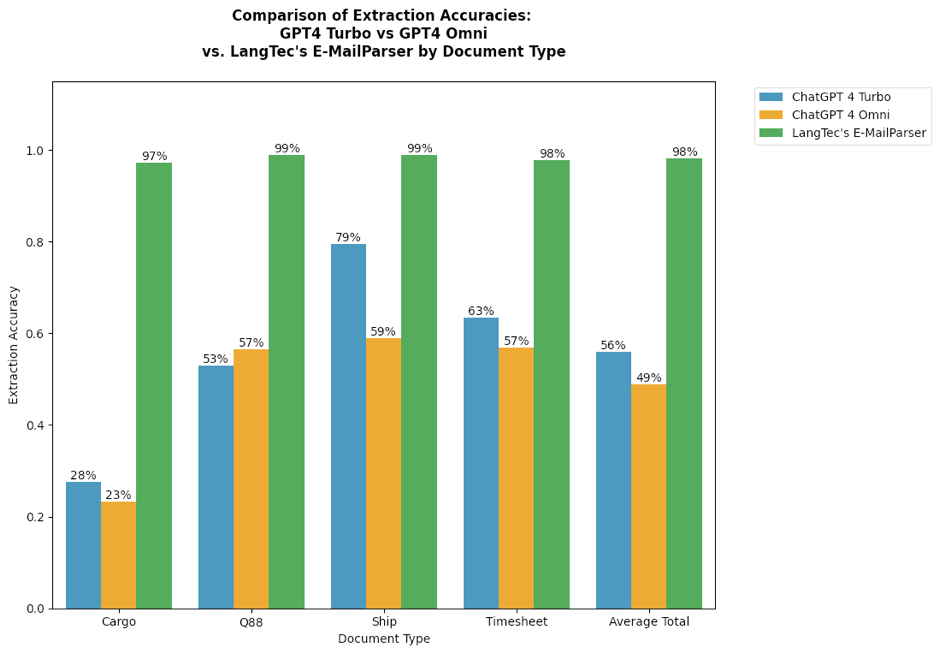
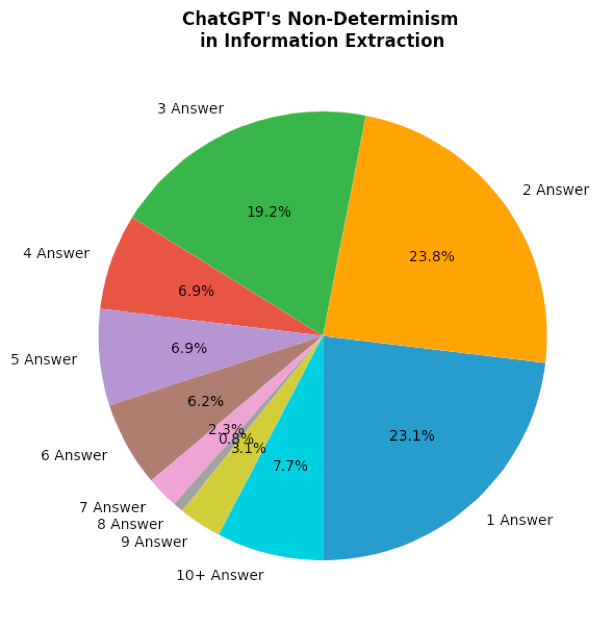
Both ChatGPT4-Turbo and ChatGPT4-Omni show some level of accuracy in information extraction tasks, achieving overall scores of 56 % and 49 % respectively. Notably, the newer model ChatGPT4-Omni performs worse on this task for most document types than its predecessor ChatGPT4-Turbo. Another important observation was that model performance is impaired by inconsistency. For the same input text and extraction task, these models provide different answers each time they are queried, even when prompted for the same question. This non-deterministic behavior renders them unreliable for scenarios where consistent and accurate information retrieval is essential.
In contrast, specialized parsers such as LangTec’s E-MailParser exhibit significantly higher accuracy, are fully deterministic in their behaviour and consistently achieve 98 % extraction accuracy across various document formats. This reliability makes a deterministic document-understanding solution like E-MailParser a more dependable solution for information extraction tasks, particularly when dealing with diverse e-mail content in business-critical applications.
Conclusion
While LLMs like ChatGPT are excellent for generating content, they have notable limitations, particularly in scenarios requiring deterministic output such as information extraction tasks. For such applications, document-understanding solutions like LangTec’s E-MailParser offer a more reliable and accurate solution.