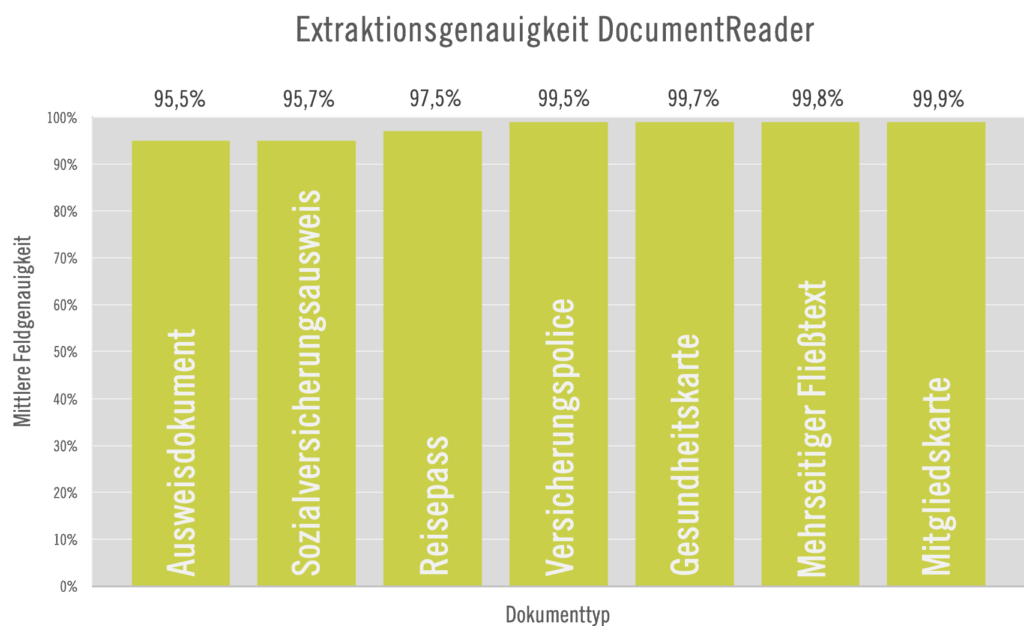
LangTecs DocumentReader – Daten Extraktion aus Dokumenten mittels Machine-learning
LangTecs DocumentReader ermöglicht mittels Machine Learning tiefgehende Informationsextraktion (IE) aus digitalisierten Dokumenten
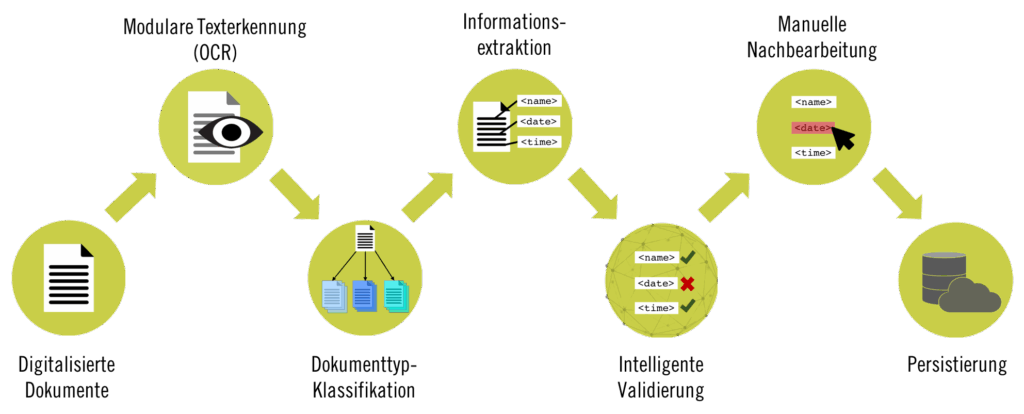
DocumentReader kann flexibel mit unterschiedlichen OCR-Engines eingesetzt werden, zum Beispiel mit ABBYY FineReader®, Tesseract oder der Google Vision API. DocumentReader erreicht hervorragende Extraktionsgenauigkeiten durch ein speziell von LangTec entwickeltes Machine-Learning-Verfahren. DocumentReader ist ein leistungsstarkes Dokumenten-Management-System (DMS) und kann auf Ihre spezifischen Bedürfnisse angepasst werden. Die Anbindung an bereits bestehende Systeme sowie die Einbindung in bestehende Infrastruktur-Kontexte sind voll flexibel möglich.