LangTec’s Information Extraction Solution from Documents Using Machine Learning
LangTec’s DocumentReader Enables High-Precision Information Extraction (IE) from Digitalised Documents
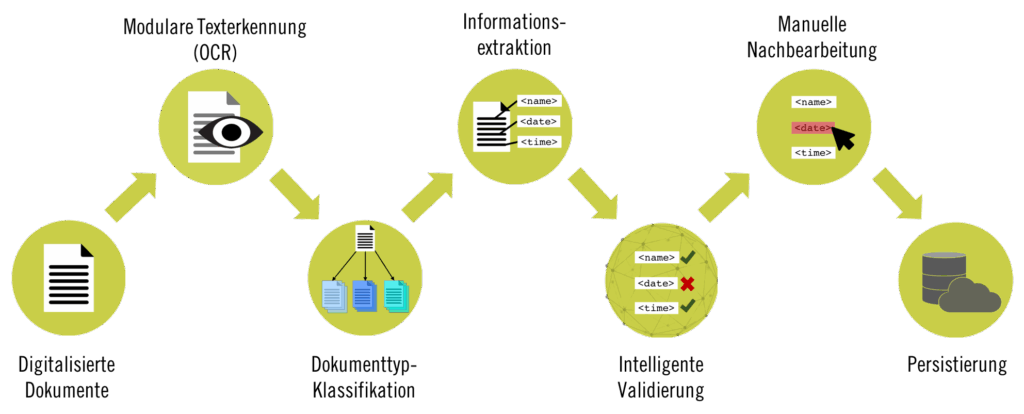
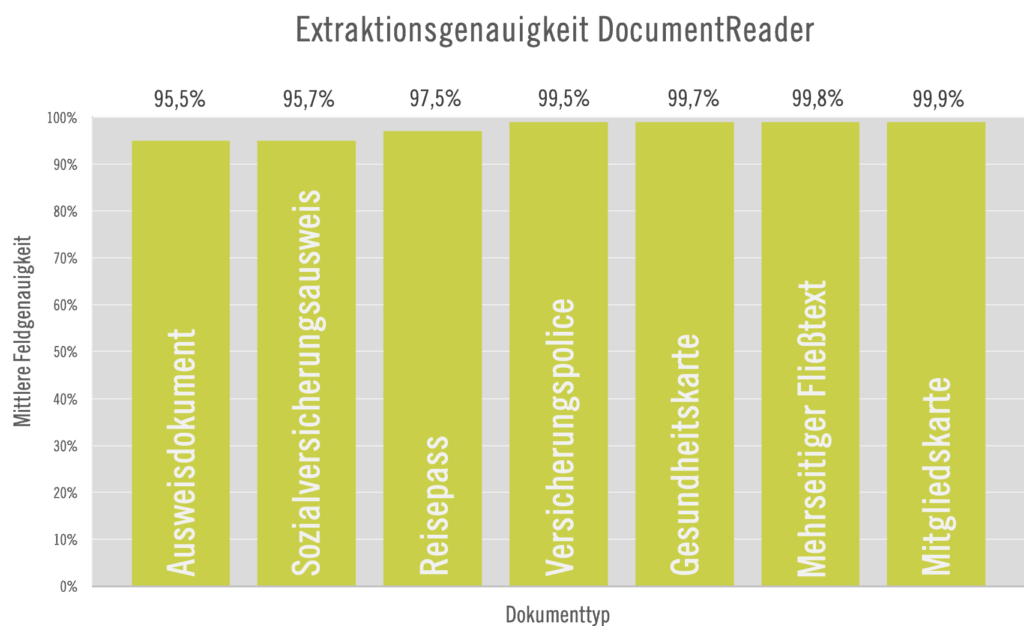
DocumentReader is highly flexible and can be used with a range of different OCR engines, such as ABBYY FineReader®, Tesseract or Google Vision API. DocumentReader achieves outstanding extraction accuracies due to its unique machine learning approach specifically developed by LangTec. DocumentReader also offers effective workflow management and seamlessly integrates into a wide range of existing application and infrastructure contexts.